This section presents a number of different solutions to the problems presented in the Specification of section 2. These include ones that have been used in the past, which could be used as the basis for a solution, along with ideas for a completely new solution to the problem.
3.1.1 CGI calls through a WWW browser
The CGI approach [7] for accessing databases across the WWW has its benefits, including ease of implementation, portability of server software and the use of standard WWW browsers as clients. It also has its limitations:
-
Sessions Problem
In most client / server systems, the client stays connected to the server through multiple transactions. With CGI, one connection is made per call to the CGI program. For Web / database interaction, this means a new database connection per query or call sent via CGI. This leads to performance degradation, and limits the client / server functionality, making it impossible to create session-oriented database applications.
-
Server Load / Scalability
All communication between the client and backend database must go through the HTTP server, with a new process created for each request to execute a CGI script. This obviously also leads to performance degradation.
-
Slow
Web browsers cannot send requests to the server asynchronously. This means that clients have to wait for the server response, which includes the time for the server to start CGI processes.
-
Limited Presentation Capabilities
The presentation of the user interface and viewing of data is restricted by HTML.
This approach has been used with success by a team at Southampton University [7] to display both standard data structures and images. Therefore, unless complex data contained within the database can be converted into a WWW browser compatible form, such as an image, then only certain data can be viewed legibly.
3.1.2 Standard Database Viewer
Jexplorer [8] is a product written to access databases in a standard way using Java Database Connectivity (JDBC). It has been written in Java and so is platform independent.
Using standard meta-data contained in all commercial databases, it can show the user the field names and types which the database contains. These details can then be used to create queries to submit to the database, the results of which can be displayed in tabular form.
This method is a good basis for the package that is needed, but again has a number of limitations:
-
Standard viewing mechanism
It only allows viewing of standard data structures. There is no way of defining how to view other structures.
-
Navigation problems
To reach the data that the user requires, means probably navigating through other unnecessary data. In addition, the user will probably need to be told where to navigate to, to retrieve that information, as it may not be immediately obvious.
-
Security problems
All users will have access to the same data, and even with different user accounts, not all databases will allow different views per user. Thus controlling access is more difficult.
3.1.3 Template mechanism
From the specification, what is actually needed is an extension to the idea of Jexplorer, which allows database administrators to select which objects within the database that users should be able to access, and how to view each one.
For each object, a viewer is provided and stored with information about the object. This set of information will be called a template. Each template is then stored in a template database, separately from the physical data, for access by a client user program. In this way, the physical data is kept completely separate and secure from the additional information provided by the templates.
Using the created templates a client user program can access and display information about each object, from which the client user can select objects to view. The selected objects can then be displayed using the viewer contained in the template.
A management tool to allow creation of these templates can use the same meta-data used by Jexplorer to present the selectable objects and the relationships between them to the database administrator, thus easing the setting up of the template database.
This template mechanism may be most useful for object-relational databases, where any amount of new data types can be defined. With these new types, the data contained within the database is of no use when viewed using a standard database viewer, but it will be very accessible with the extra viewers made available through the templates.
This section presents possible environments and programming languages in which to implement the template mechanism presented above. Section 3.4 presents the actual choice of environment that has been made.
3.2.1 Microsoft Visual Basic v5.0
Pros
- Can design interface graphically
- Easy to set-up network socket connections
- Easy to set-up links to many different vendors’ databases through ODBC
- The developer knows it well
Cons
- Platform dependent (both program and database access)
- Not easy to load up separate modules and communicate with them (ActiveX files can be run, but communicating with them is more difficult to implement)
3.2.2 Microsoft Visual C++, Borland C++
Pros
- Can design interface graphically
- Easy to set-up network socket connections
- Easy to set-up links to many different vendors’ databases through ODBC
- The developer knows it quite well, although has never done any work with databases through it
- Good modular structure
Cons
- Platform dependent in many ways, especially in terms of graphics, network sockets and accessing databases
3.2.3 Java
Pros
- Platform independent
- Easy to set up network socket connections
- Easy to set-up links to many different vendors’ databases using JDBC
- Can recreate and execute modules after they have been converted to a flat file
Cons
- The developer has not used it very much before, but it is very similar to C++ in many ways
- Not as easy to set up an interface
There are also different development environments for Java to consider
3.2.3.1 IBM Visual Age for Java
Pros
- Can design interfaces graphically
- Can edit program code dynamically during program execution
- Compilation is done automatically during development, without the need to recompile before executing each program
- Versioning of software components is well controlled
- Can access databases through specialised Java Beans which are integrated into the software
Cons
- The developer has never used this development environment before
3.2.3.2 Symantec Visual Café, Sun Java Workshop
Pros
- Can design interfaces graphically
Cons
- The developer did not find either of these products as easy to use as Visual Age for Java
This section presents possible databases in which to develop the template mechanism presented above. Section 3.4 presents the actual choice of database that was made.
3.3.1 Microsoft Access
Pros
- Easy to use graphical interface for setting up tables and queries
- Contains a field structure which can hold up to 32Mb of data per record (e.g. this structure could be useful for storing viewers)
- The developer knows it well
- Easy to transport databases between different machines for testing purposes
Cons
- No specific JDBC driver, and so could only be tested using ‘JDBC/ODBC Bridge’ JDBC driver
3.3.2 IBM DB2
Pros
- Used by the university for many database applications, and is the database of choice for use on the IBM SP2 parallel computer
- Contains a field structure which can be defined to hold as much data as is necessary (e.g. this structure could be useful for storing viewers)
- It is an object-relational database, and so supports user-defined types and functions for creating and accessing complex data structures
- Has specific JDBC drivers written for it for both local and network access
- Has a scripting language to ease setting up of databases on multiple machines
Cons
- The developer has never used it before
- Not easy to transport databases between different machines for testing purposes
It was decided that the packages to be used for development should be chosen based more on functionality, rather than how experienced the developer was at using them. Ease of use and experience of the developer would also be useful features though.
Both the management tool and client user programs are to be written in Java to be platform independent. The ease of accessibility to databases and its coding similarities to C++ were also of interest in making this choice. Viewers can be written in Java, and an API can be provided for to allow viewers to interact with the system.
For access to the databases themselves, the JDBC mechanism is to be used. JDBC offers an abstraction level, allowing many different commercial databases to be accessible in a standard way.
The environment chosen for development is IBM Visual Age for Java due to its ease for development of the user interface and code.
The database package chosen for developing and testing the template mechanism is IBM DB2. This has its own JDBC driver for accessing both local and networked databases, but most importantly it contains a field structure which can be used to hold Java applications, which will be useful for storing the viewers.
The system needs to allow many users to connect to one central template database, and one or more data databases. Two methods could be used to achieve this [1, 2].
3.5.1 Two-tier model
The client user program can be connected directly to the template and data databases using JDBC (Figure 3.5.1). Unfortunately, the user then needs to know the exact URL for this database, along with the driver to use, and a user name and password to gain access. All of this, the database administrator would have to set-up and distribute, and any movement of the data, or structure of the data, would mean updating the client user program every time.
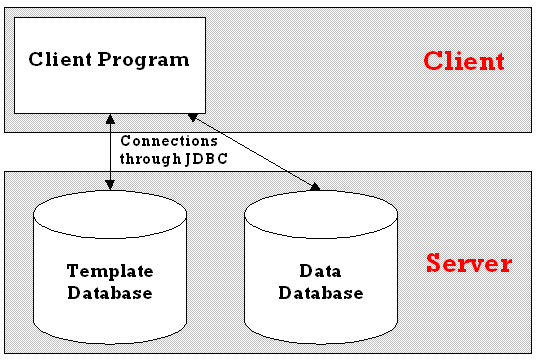
Figure 3.5.1
3.5.2 Three-tier model
In contrast, the client user program could connect to a separate program running on the server, that in turn is connected to the template database using JDBC (Figure 3.5.2). This server program would then have to be given the URL, driver, user name and password to use, but these details would only need to be known by the database administrator. They would not need to be distributed, as the client user program would only need to know the IP address and port number on which the server program was running to be able to connect to it.
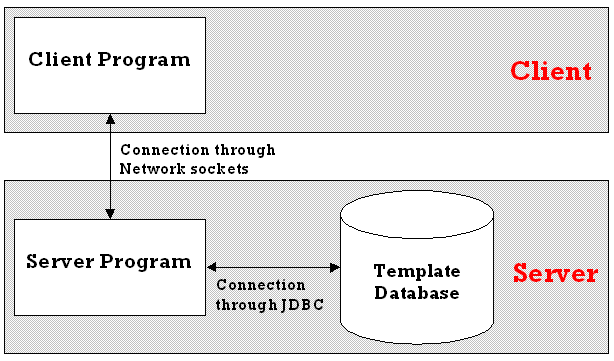
Figure 3.5.2
This sets up the connection to the template database very simply, and allows the data and structure of it to be changed, without having to update every client user program. The server program could then be updated, and still run on the same machine and port number, without the client user program even knowing anything had happened.
When accessing the data database (Figure 3.5.3), connection information is again needed, but this can be stored separately with the templates for download as necessary. Thus, it is again only known by the database administrator. In this way, a viewer can connect to the data database using a standard method provided by the API. This will allow the default viewing mechanism to be implemented simply as well.
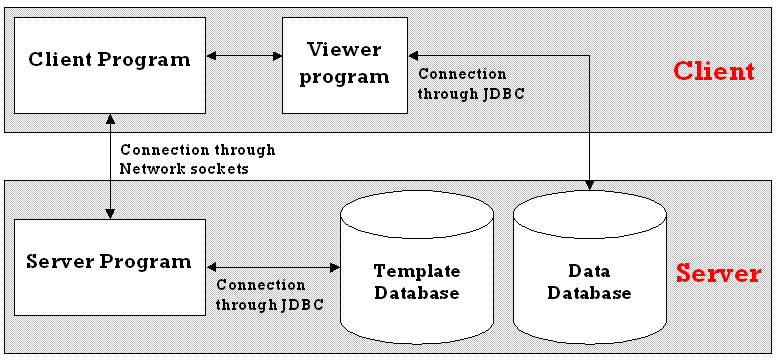
Figure 3.5.3
With this structure, the database administrator has complete control over movement of data and template information without affecting the external client users, as long as the host name and port number of the server program do not change.
3.5.3 Client Local Cache
The viewer programs to be used by the client will need to be downloaded from the server to allow them to be executed. To reduce the amount of downloads necessary, a local cache of viewers will be built up, and if the server ever updates a viewer, the new version will be downloaded into the cache. In this way, the client will be able to use the same viewer repeatedly, without wasting time waiting for it to be downloaded every time from the server.
3.5.4 Management Tool
Separate from the client and server programs, there needs to be a management tool, to allow setting up of the templates. This tool will need to be able to access the template database, along with the structure of the data databases directly. It will only be used by the database administrator and so any change of location or user name / password combination for accessing the database will be known. A two-tier structure (Figure 3.5.4) is probably the simplest, and easiest to use and implement in this instance.
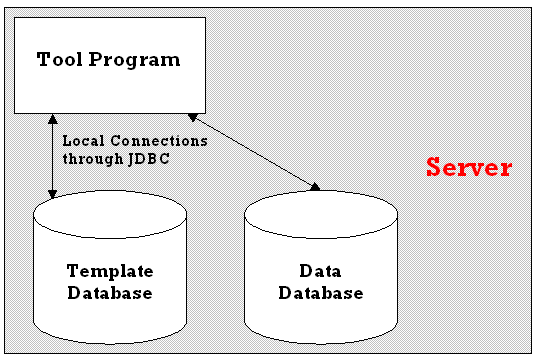
Figure 3.5.4
From the observations above, a three tier model for the main client / server / template database interaction has been decided upon, along with a two-tier model for the tool / template database / data databases interaction.
The three-tier model offers database administrators the ease of moving databases and their objects around, and changing viewer applications, without having to update client users manually. The user can just connect to the server application, and let it decide on the necessary queries to send to whatever template database the administrator wishes, so that the correct information can be sent to the client. Many server applications could also be running on the same machine, all connected to different template databases, so that clients can connect to a different process depending on what view of the data they require.
The two-tier model was chosen for the management tool, because it will need to access the databases directly anyway. Also there will not usually be more than one user needing to use the tool on the same template database at any one time. Thus, routing the processing of commands through a separate server program would be a waste of resources, and a waste of the extra implementation time that would be necessary to do create such a second-tier program.
Following these models, data flow diagrams for the client, server and management tool programs have all been created to describe the design of the system. These, along with the data dictionary are shown in Appendix 1.
It should be noted, that although the above model is built around a single data database on one machine, it is believed that this can easily be extended to multiple or distributed [3] data databases. Templates can be set up about objects in each separate data database and be contained in the one template database by storing connection information with the templates