| Name: | Theo Gray | [email protected] |
Supervisor: |
Flavio Bergamaschi | [email protected] |
Second Supervisor: |
Stephen O'Connell | [email protected] |
Project Title: |
Abstract Database Viewer: An API for Automatic Database Information Retrieval Through the Internet | |
This progress report has been developed over the past few months as discoveries have been made into how to achieve each part of the design.
In this report, a full project description, along with the choice of development environments is given. This is followed by the proposed final system design, my work and findings so far, and finally the work which still needs to be done.
All references are given at the end of this report.
Databases are an integral part of many businesses around the world. Through the Internet or a local Intranet, it is possible for these databases to be made accessible to whomever the company wishes. The problem with this is that the data contained in a database is made up of a fixed number of standard types and any database viewer will only allow viewing of these fields in a standard way. In some cases, such as the data being a picture, or an audio clip, this will mean that garbage is shown to the user, which is of no use whatsoever.
I propose to create an API for database programmers, which allows them to make these databases, and any others, accessible and readable, by adding semantic information and applets for viewing the data, to the database. I also propose to create a tool to allow them to add this information as easily as possible.
For interacting with these databases, I propose to create a two-tier[2] Java application[1]. The client application will consist of minimal code to reduce download time. It will be able to connect to, retrieve and display information from the server application, which, in turn, will make the connections and retrieve the actual data from the database to pass back to the client.
The API and its related applications should be able to run on any platform, across the Internet or an Intranet. These will be programmed in Java[1], which makes that possible, and should connect to any database that supports the ODBC or JDBC protocols[2]. Many large companies may well have distributed databases[3], and so the system will be able to work across these using a Java IDL and CORBA[4].
The system will be developed using IBM's Visual Age for Java (VAJ) along with an IBM DB2 database (DB2). The choice of coding environment has been made due to the relative ease of development within VAJ compared to packages such as Symantec's Visual Café and Java Workshop from Sun. It has built in visual development with the coding environment and has an easy way of setting up attachments to databases. DB2 was chosen for setting up the test database because it has support for binary large objects (BLOBs) which will allow storing of Java applets for viewing data, within the database itself.
The design of the system has been developing whilst I have been finding out about all the different parts of the system which need to be implemented. This section gives a proposal for the final design of each part of the system.
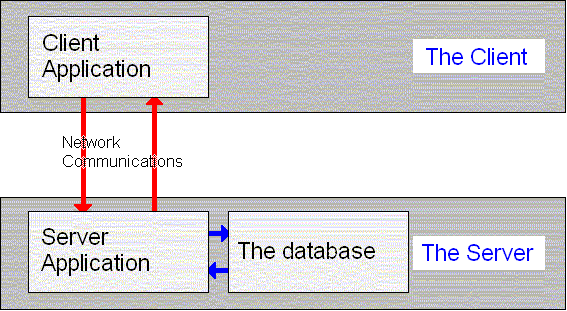
The proposed final design is made up of two applications - the Client application and the Server application, as mentioned in the project description above. These will communicate with each other over a network and the Server application will also communicate with the database:
This will consist of a simple user interface that will allow the user to
connect to any known database and issue commands to retrieve data from it. The
designer of the database will already have decided on the views of the data
that the user is allowed to see, and the fields within the data that need
special viewers. Whenever the client selects to view some data, it will either
show that data through a standard text based viewer such as those used in [7]
or [8], or through a custom viewer which the designer of the
database has written.
When the client connects to the database, they will actually be doing so through a program running alongside the database. This will allow decisions about what needs to be sent to the client to be made locally to the database, minimising unnecessary communication between the client and the database.
For the idea behind the system to work completely, the designer of the database will need to enter template information into tables within the database. The server application can then analyse this extra data, so that it can know what information to send to the client, and how the client should display it. This can be done by hand into the two template tables that will be structured as follows:
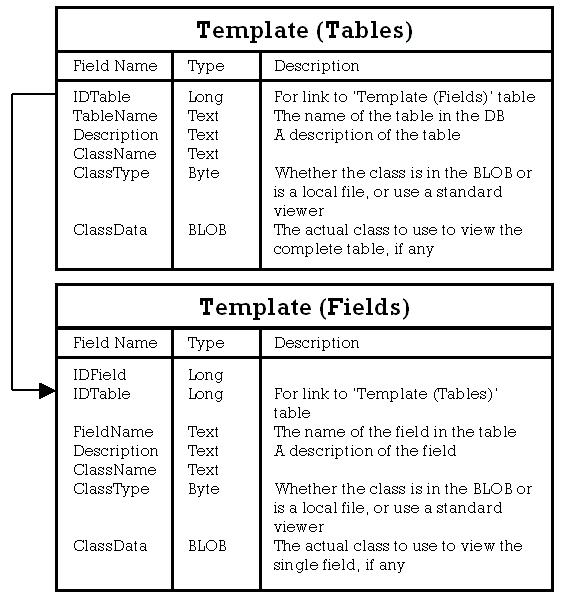
Ideally, this should be done through a tool though, as specified in the project description above. This tool will analyse the database and any relationships declared in it and display its findings to the designer. The designer can then edit it if necessary, choosing the database views which the client will be allowed, and adding any applets necessary to view the data. I believe that this is a very simple structure, but should also be very powerful.
If the data to be viewed is not of a type which could be displayed by a standard text viewer, then the designer of the database will need to provide their own viewer. For example, if the data was a picture, the designer would need to provide a picture viewer. These viewers will be constructed as Java applets, again so that the program can be run on any platform.
These applets are to be stored within the ClassData fields of the
database. If this is not possible (i.e. there is no way of storing
Binary Large Objects (BLOBs) (as they are called in DB2), or a similar database
field structure that can store binary fields), the applets can also be stored
as separate files alongside the database.
This design may change over the next few months if the procedures involved in implementing it are not possible within the time available, but this is a proposal for the design as it is seen now.
To test the program initially, I am developing the basics of the Ai Solutions CDM ToolKit v3.1[9] into a working DB2 database, and adding the template data necessary to allow it to be viewed using the Abstract Database Viewer.
The past few months have involved high learning curves at times. This all began with learning how to program in Java, and in particular, how to use VAJ, and create and access databases using DB2 along with JDBC. This knowledge has been developed from previous experience in C++ and the Microsoft Access database. The transition from C++ to Java was not too great, but the specifics of calls to JDBC, especially alongside DB2, have been more difficult to learn.
Learning VAJ, I have now worked with two subsequent versions. Having learnt how to use the Java compiler and classes, and how to link to ODBC compliant databases (using the JDBC ODBC Bridge driver classes supplied by Sun), it has taken a while to find out how to access all of the extra JDBC classes and any other classes which I have needed to. This was a problem for a while, but was eventually solved by importing the classes into VAJ.
Once these problems had been solved, I worked out how to set up DB2 database tables, how to import data into them, and used Lotus Approach to edit the data manually when necessary.
Within Java, I have also had two other problems. The first was one of loading
a class or applet into memory and accessing it. This was solved by creating an
interface that the new applet could implement, and using the java.lang.Classloader
class to load the applet into memory. The second problem was how to put this
applet into the BLOB field within the template table and retrieve it. This
problem has not yet been solved, despite queries for help to various news
groups, user forums, and IBM Java developers. I have decided to work around
this for the moment, as my current ClassLoader class will load and
execute from files without error, and I can continue without loading
specifically from the database without a problem.
There is still plenty of work to be done on the system, although most of the major problems have been solved so far. The problem of how to load data from the BLOB field of a DB2 database is still to be solved, as is how exactly to split the main application into client and server parts, as I have decided to develop the two as one application, until it needs to be split in two.
Once the main application is written, the tool to allow the designer to edit the templates will need to be written, and the logic for parsing the database tables and relations is still to be written.
Finally, the product will need to be thoroughly tested using a plan, which is yet to be drawn up.
The system design has been done, and most of the problems have been solved. It is now a matter of moving the ideas on into a working system, and creating the tools to aid database designers in using it.
Gary Cornell and Cay S. Horstmann, Core Java, Second Edition, Prentice Hall, 1997.
Prashant Sridharan, Advanced Java Networking, Prentice Hall, 1997.
S. Ceri and G. Pelgatti, Distributed Databases: Principles and Systems, McGraw-Hill, New York, 1984.
Andreas Vogel and Keith Duddy, Java Programming with CORBA, Wiley Computer Publishing, 1997.
Various Java sites, which can be accessed from
http://www.ecs.soton.ac.uk/~tjg295/project/JavaLinks.html
On-line log book
http://www.ecs.soton.ac.uk/~tjg295/project/log/index.html
Mark Papiani, Alistair N. Dunlop and Anthony J. G. Hey, Automatically Generating World-Wide Web Interfaces to Relational Databases, University of Southampton, 29th November, 1996
Bernard Van Haecke, JDBC Java Database Explorer, 1996
Ai Solutions
http://www.AiSolutions.co.uk
Theo Gray:
[email protected]
http://www.theogray.com