CM391 - Final Report
Abstract
Databases are an integral part of many businesses around the world. Through the Internet or an Intranet, it is possible for these databases to be made accessible to whomever the company wishes. The problem is that interested parties wish to view the data, without the need for installation of extra software every time they want to access a different database.
There are various solutions to this, but in general, they all suffer from similar drawbacks, including problems of navigation, security and viewing of complex data structures.
Another problem, separate from the functionality of the solution, is that the data is to be accessed through the Internet, or an Intranet. Thus, it needs to be useable on many different machine architectures and operating systems, working in a similar way in all cases.
Written in JavaTM, to be platform independent, the Abstract Database Viewer (ADBV) has been developed as a solution to these problems. It presents an API, which allows database administrators to link the meta-data that is contained in all commercial databases to separate viewer applications. This allows any data structures contained in the database, simple or complex, to be accessed through a standard interface by any user.
The following document describes the processes that were involved in analysing, designing, implementing and testing the ADBV solution, and the future development that could enhance the current system.
Contents
Abstract
Acknowledgements
1. Introduction
1.1 Problem Definition
1.2 Objectives
1.3 Constraints
2. Specification of Requirements
2.1 Introduction
2.2 General Description
2.3 Environment
2.4 Visual Display
2.5 Error Handling
2.6 Deliverable Items
3. Analysis
3.1 Possible solutions and related work
3.2 Possible development environments for implementation
3.3 Possible development databases
3.4 Chosen packages
3.5 Structure
3.6 Data Flow Diagrams
4. Design
4.1 Subsystems
4.2 Data Structures
4.3 File Design
4.4 Object Diagrams
4.5 Testing Design
5. Implementation
5.1 Development
5.2 Listings
5.3 User Documentation
5.4 System Maintenance
6. Testing
6.1 Test Plan
6.2 Test Report
7. Conclusions and Future Work
8. References
Appendix 1: Data Flow Diagrams
1. Client
2. Server
3. Tool
4. Data Dictionary
Appendix 2: Information about the accompanying disk
Appendix 3: User Documentation
Flavio Bergamaschi came up with the original idea of including template information with a database. His support throughout the project, with information, ideas, and moral has been invaluable throughout this work.
IBM supplied the development environment and database package. JMD Systems upgraded the hardware of the development system to one that has performed well over the past few months.
Steve Stearns, Paul Copeland, Steve O’Connell and Alistair Dunlop were of help with information relating to DB2 BLOB fields when it seemed that there was just no solution to the problem.
A quick, but worthy note of thanks to Mark Papiani, who remembered a small bit of information which saved a search through all of the DB2 documentation.
Thanks also to the University of Southampton’s Department of Electronics and Computer Science who saved a lot of Internet download time.
Finally, thanks to Leslie Wilmart-Angelo who has helped with ideas, and Simon Kampa who has helped in the testing of the package.
Databases are an integral part of many businesses around the world. Through the Internet or an Intranet, it is possible for these databases to be made accessible to whomever the company wishes. Employees, clients, distributors, or other interested third parties may all wish to view the data contained therein, without the need for installation of extra software, every time they want to view a different database.
There are various solutions to this, but in general, they all suffer from similar drawbacks, including problems of navigation, security and viewing of non-standard data.
Another problem, separate from the functionality of the solution, is that the data is to be accessed through the Internet, or an Intranet. Thus, it needs to be useable on many different machine architectures and operating systems, working in a similar way in all cases.
A database-viewing package is needed, which allows an external user to access the specific information they require in a structured and controlled way. The format of this information, and the type of database and platform, wherever the information resides, should not matter.
The package should contain all of the necessary programs to allow the database administrator to set up the database for access, and the client user to retrieve the information they require as quickly, and as easily as possible.
A detailed specification follows in Section 2.
The package is to be completed within ten months.
As this is an Internet package, so it should be designed to run on as many different machine architectures, operating systems and databases as possible, in a standard way.
There should be a common look and feel between all programs included within the package
This section represents a specification for a package that is required to enable the viewing of data across the Internet or an Intranet.
Databases are an integral part of many businesses around the world. Through the Internet or an Intranet, it is possible for these databases to be made accessible to whomever the company wishes. Employees, clients, distributors, or other interested third parties may all wish to view the data contained therein, without the need for installation of extra software, every time they want to view a different database.
A package is required which allows a client user to view specific information from the database in a controlled and structured way, allowing viewing of not only simple data structures, but also complex ones. Thus, it needs to go beyond the functionality of a standard database viewer; i.e. one that presents the complete structure of the database to the user, and only allows viewing of standard data structures.
For the package to display only specific information, and do so in a controlled way, extra information about the data will have to be created describing what can be viewed by client users and, if necessary, how to view it. Thus, to complete the package, a management tool will be needed to allow database administrators to create the extra information as quickly as possible.
Once the package has been installed, it should not be necessary for the client user to install any other components, except for upgrade purposes. Downloading of new viewing mechanisms for unknown data structures should be done automatically by the package, with as little user intervention as possible.
The package needs to be able to access as many different types of commercial database as possible. These types include the traditional and widely used relation database model [5 p.7.18] and object-relational databases [5 p.7.34]. The database could also be on a single machine, or distributed across many machines, and even platforms.
2.3 Environment
The viewing package will be run on machines connected to the Internet or an Intranet. As such, it is not known what architecture the machines will be, or on what operating system the program will be run. Therefore, it should be possible to run it on as many different machine architectures and operating systems as possible.
The management package also needs to access as many different vendors’ databases as possible and do so from as many different platforms as possible.
The on-screen display should have a common look and feel throughout the package, and should be as easy and informative to use as possible.
It is essential that error-handling techniques be provided to ensure that the program does not crash if an unexpected event occurs, or a user tries to do something unexpected.
Appropriate warning messages should be provided, depending on the severity of the error.
The following deliverable items are required:
- Executable programs for both client users and the database administrator
- Clear installation notes
- Comprehensive, but simple to understand User Documentation
This section presents a number of different solutions to the problems presented in the Specification of section 2. These include ones that have been used in the past, which could be used as the basis for a solution, along with ideas for a completely new solution to the problem.
3.1.1 CGI calls through a WWW browser
The CGI approach [7] for accessing databases across the WWW has its benefits, including ease of implementation, portability of server software and the use of standard WWW browsers as clients. It also has its limitations:
-
Sessions Problem
In most client / server systems, the client stays connected to the server through multiple transactions. With CGI, one connection is made per call to the CGI program. For Web / database interaction, this means a new database connection per query or call sent via CGI. This leads to performance degradation, and limits the client / server functionality, making it impossible to create session-oriented database applications.
-
Server Load / Scalability
All communication between the client and backend database must go through the HTTP server, with a new process created for each request to execute a CGI script. This obviously also leads to performance degradation.
-
Slow
Web browsers cannot send requests to the server asynchronously. This means that clients have to wait for the server response, which includes the time for the server to start CGI processes.
-
Limited Presentation Capabilities
The presentation of the user interface and viewing of data is restricted by HTML.
This approach has been used with success by a team at Southampton University [7] to display both standard data structures and images. Therefore, unless complex data contained within the database can be converted into a WWW browser compatible form, such as an image, then only certain data can be viewed legibly.
3.1.2 Standard Database Viewer
Jexplorer [8] is a product written to access databases in a standard way using Java Database Connectivity (JDBC). It has been written in Java and so is platform independent.
Using standard meta-data contained in all commercial databases, it can show the user the field names and types which the database contains. These details can then be used to create queries to submit to the database, the results of which can be displayed in tabular form.
This method is a good basis for the package that is needed, but again has a number of limitations:
-
Standard viewing mechanism
It only allows viewing of standard data structures. There is no way of defining how to view other structures.
-
Navigation problems
To reach the data that the user requires, means probably navigating through other unnecessary data. In addition, the user will probably need to be told where to navigate to, to retrieve that information, as it may not be immediately obvious.
-
Security problems
All users will have access to the same data, and even with different user accounts, not all databases will allow different views per user. Thus controlling access is more difficult.
3.1.3 Template mechanism
From the specification, what is actually needed is an extension to the idea of Jexplorer, which allows database administrators to select which objects within the database that users should be able to access, and how to view each one.
For each object, a viewer is provided and stored with information about the object. This set of information will be called a template. Each template is then stored in a template database, separately from the physical data, for access by a client user program. In this way, the physical data is kept completely separate and secure from the additional information provided by the templates.
Using the created templates a client user program can access and display information about each object, from which the client user can select objects to view. The selected objects can then be displayed using the viewer contained in the template.
A management tool to allow creation of these templates can use the same meta-data used by Jexplorer to present the selectable objects and the relationships between them to the database administrator, thus easing the setting up of the template database.
This template mechanism may be most useful for object-relational databases, where any amount of new data types can be defined. With these new types, the data contained within the database is of no use when viewed using a standard database viewer, but it will be very accessible with the extra viewers made available through the templates.
This section presents possible environments and programming languages in which to implement the template mechanism presented above. Section 3.4 presents the actual choice of environment that has been made.
3.2.1 Microsoft Visual Basic v5.0
Pros
- Can design interface graphically
- Easy to set-up network socket connections
- Easy to set-up links to many different vendors’ databases through ODBC
- The developer knows it well
Cons
- Platform dependent (both program and database access)
- Not easy to load up separate modules and communicate with them (ActiveX files can be run, but communicating with them is more difficult to implement)
3.2.2 Microsoft Visual C++, Borland C++
Pros
- Can design interface graphically
- Easy to set-up network socket connections
- Easy to set-up links to many different vendors’ databases through ODBC
- The developer knows it quite well, although has never done any work with databases through it
- Good modular structure
Cons
- Platform dependent in many ways, especially in terms of graphics, network sockets and accessing databases
Pros
- Platform independent
- Easy to set up network socket connections
- Easy to set-up links to many different vendors’ databases using JDBC
- Can recreate and execute modules after they have been converted to a flat file
Cons
- The developer has not used it very much before, but it is very similar to C++ in many ways
- Not as easy to set up an interface
There are also different development environments for Java to consider
3.2.3.1 IBM Visual Age for Java
Pros
- Can design interfaces graphically
- Can edit program code dynamically during program execution
- Compilation is done automatically during development, without the need to recompile before executing each program
- Versioning of software components is well controlled
- Can access databases through specialised Java Beans which are integrated into the software
Cons
- The developer has never used this development environment before
3.2.3.2 Symantec Visual Café, Sun Java Workshop
Pros
- Can design interfaces graphically
Cons
- The developer did not find either of these products as easy to use as Visual Age for Java
This section presents possible databases in which to develop the template mechanism presented above. Section 3.4 presents the actual choice of database that was made.
3.3.1 Microsoft Access
Pros
- Easy to use graphical interface for setting up tables and queries
- Contains a field structure which can hold up to 32Mb of data per record (e.g. this structure could be useful for storing viewers)
- The developer knows it well
- Easy to transport databases between different machines for testing purposes
Cons
- No specific JDBC driver, and so could only be tested using ‘JDBC/ODBC Bridge’ JDBC driver
3.3.2 IBM DB2
Pros
- Used by the university for many database applications, and is the database of choice for use on the IBM SP2 parallel computer
- Contains a field structure which can be defined to hold as much data as is necessary (e.g. this structure could be useful for storing viewers)
- It is an object-relational database, and so supports user-defined types and functions for creating and accessing complex data structures
- Has specific JDBC drivers written for it for both local and network access
- Has a scripting language to ease setting up of databases on multiple machines
Cons
- The developer has never used it before
- Not easy to transport databases between different machines for testing purposes
It was decided that the packages to be used for development should be chosen based more on functionality, rather than how experienced the developer was at using them. Ease of use and experience of the developer would also be useful features though.
Both the management tool and client user programs are to be written in Java to be platform independent. The ease of accessibility to databases and its coding similarities to C++ were also of interest in making this choice. Viewers can be written in Java, and an API can be provided for to allow viewers to interact with the system.
For access to the databases themselves, the JDBC mechanism is to be used. JDBC offers an abstraction level, allowing many different commercial databases to be accessible in a standard way.
The environment chosen for development is IBM Visual Age for Java due to its ease for development of the user interface and code.
The database package chosen for developing and testing the template mechanism is IBM DB2. This has its own JDBC driver for accessing both local and networked databases, but most importantly it contains a field structure which can be used to hold Java applications, which will be useful for storing the viewers.
The system needs to allow many users to connect to one central template database, and one or more data databases. Two methods could be used to achieve this [1, 2].
3.5.1 Two-tier model
The client user program can be connected directly to the template and data databases using JDBC (Figure 3.5.1). Unfortunately, the user then needs to know the exact URL for this database, along with the driver to use, and a user name and password to gain access. All of this, the database administrator would have to set-up and distribute, and any movement of the data, or structure of the data, would mean updating the client user program every time.
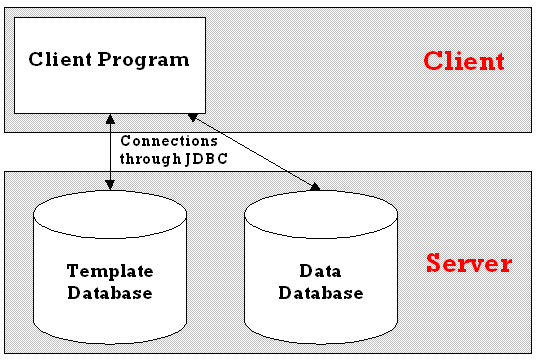
Figure 3.5.1
3.5.2 Three-tier model
In contrast, the client user program could connect to a separate program running on the server, that in turn is connected to the template database using JDBC (Figure 3.5.2). This server program would then have to be given the URL, driver, user name and password to use, but these details would only need to be known by the database administrator. They would not need to be distributed, as the client user program would only need to know the IP address and port number on which the server program was running to be able to connect to it.
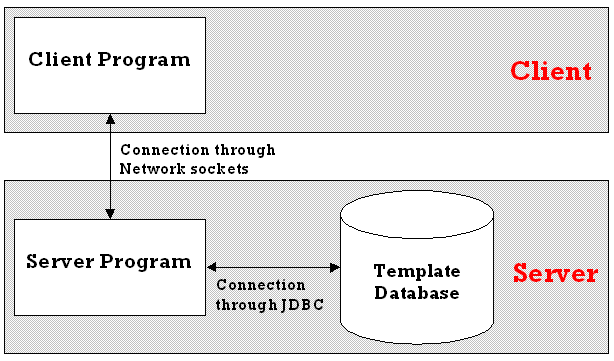
Figure 3.5.2
This sets up the connection to the template database very simply, and allows the data and structure of it to be changed, without having to update every client user program. The server program could then be updated, and still run on the same machine and port number, without the client user program even knowing anything had happened.
When accessing the data database (Figure 3.5.3), connection information is again needed, but this can be stored separately with the templates for download as necessary. Thus, it is again only known by the database administrator. In this way, a viewer can connect to the data database using a standard method provided by the API. This will allow the default viewing mechanism to be implemented simply as well.
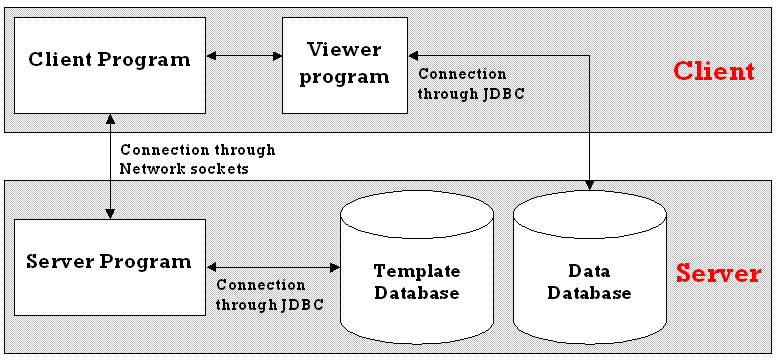
Figure 3.5.3
With this structure, the database administrator has complete control over movement of data and template information without affecting the external client users, as long as the host name and port number of the server program do not change.
3.5.3 Client Local Cache
The viewer programs to be used by the client will need to be downloaded from the server to allow them to be executed. To reduce the amount of downloads necessary, a local cache of viewers will be built up, and if the server ever updates a viewer, the new version will be downloaded into the cache. In this way, the client will be able to use the same viewer repeatedly, without wasting time waiting for it to be downloaded every time from the server.
3.5.4 Management Tool
Separate from the client and server programs, there needs to be a management tool, to allow setting up of the templates. This tool will need to be able to access the template database, along with the structure of the data databases directly. It will only be used by the database administrator and so any change of location or user name / password combination for accessing the database will be known. A two-tier structure (Figure 3.5.4) is probably the simplest, and easiest to use and implement in this instance.
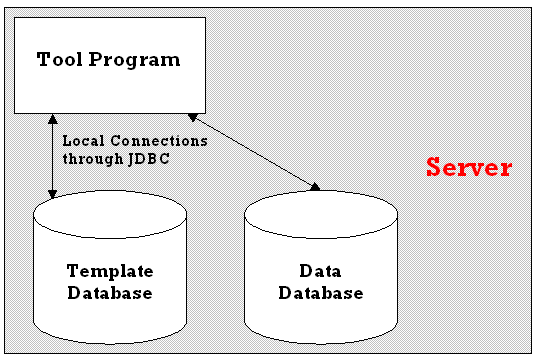
Figure 3.5.4
From the observations above, a three tier model for the main client / server / template database interaction has been decided upon, along with a two-tier model for the tool / template database / data databases interaction.
The three-tier model offers database administrators the ease of moving databases and their objects around, and changing viewer applications, without having to update client users manually. The user can just connect to the server application, and let it decide on the necessary queries to send to whatever template database the administrator wishes, so that the correct information can be sent to the client. Many server applications could also be running on the same machine, all connected to different template databases, so that clients can connect to a different process depending on what view of the data they require.
The two-tier model was chosen for the management tool, because it will need to access the databases directly anyway. Also there will not usually be more than one user needing to use the tool on the same template database at any one time. Thus, routing the processing of commands through a separate server program would be a waste of resources, and a waste of the extra implementation time that would be necessary to do create such a second-tier program.
Following these models, data flow diagrams for the client, server and management tool programs have all been created to describe the design of the system. These, along with the data dictionary are shown in Appendix 1.
It should be noted, that although the above model is built around a single data database on one machine, it is believed that this can easily be extended to multiple or distributed [3] data databases. Templates can be set up about objects in each separate data database and be contained in the one template database by storing connection information with the templates
This section presents details of the subsystems, data structures, file structures and testing design for the system.
It has been decided to name the system the Abstract Database Viewer (ADBV), due to its abstract nature of being able to work with almost any commercial database on almost any machine around the world.
This section presents the system flow diagrams for each of the client, server and tool programs within the package, along with descriptions of and any issues involved with each program
4.1.1 Client
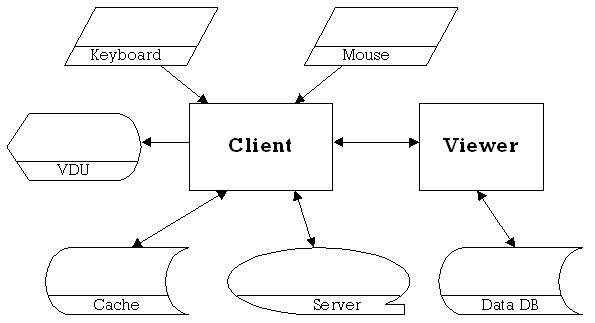
Figure 4.1.1
The client user program will take direct input from the user through the keyboard and mouse.
Communication will take place between the client and the server, to allow retrieval of any information necessary so that the user can access the viewers, and ultimately the actual data of the database.
There is a local cache of previously used viewers, so that the same viewer does not need to be downloaded more than once.
There are issues involved with the client user program, relating to the versioning of downloaded viewers. A mechanism needs to be implemented to allow viewers that are currently in the cache, to be updated as necessary. A version number and last updated date should suffice.
Other issues relate to communication with the server, which needs to be controlled so that information is not mixed up by sending multiple commands at any one time.
4.1.2 Server
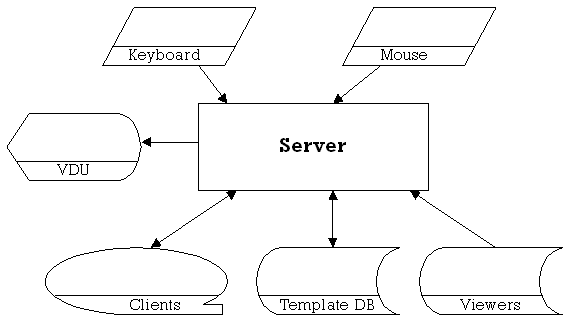
Figure 4.1.2
The server program will take direct input from the user through the keyboard and mouse to allow it to be started. Once started, it will read data from the template database and viewers, and communicate with any attached clients, with the only other user input being needed to stop the program when all users have disconnected.
4.1.3 Tool
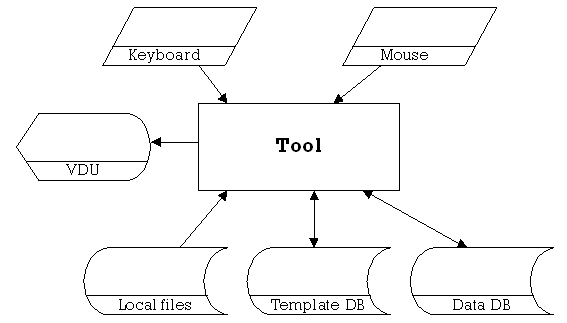
Figure 4.1.3
The tool will take direct input from the user through the keyboard and mouse.
It will read in viewer data from local files as necessary, and read meta-data from the data databases. Templates for each object, along with any options necessary, will be stored within the template database.
The data and template databases may be stored locally, or externally, as the JDBC mechanism will work with either.
ADBV is to be written using Java, and so the data structures involved are classes and interfaces, which are grouped together in packages.
The distribution of ADBV is to be in two separate versions - Administrative and Client.
- ADBV Administrative will contain all of the data structures necessary to set up the template databases (through the Tool program), and to allow Client users to access the template data (through the Server program).
- ADBV Client will contain just those data structures necessary to allow a user to connect to a Server program (through the Client program), and access and view data.
To aid control of this distribution, four Java packages have been created. Each of the three programs (Client, Server and Tool) consists of a separate Java package named using the program name prefixed by ADBV (i.e. ADBVClient, ADBVServer, ADBVTool respectively). The other package contains classes used by the user interface of each of the three programs.
The following sub-sections contain simple descriptions of each package and the data structures contained within them.
For a more complete description of each public data structure (signified by  ), the accompanying disk contains documentation produced directly from the source code using a program called JavaDoc. (See Appendix 2 for information about the accompanying disk.)
), the accompanying disk contains documentation produced directly from the source code using a program called JavaDoc. (See Appendix 2 for information about the accompanying disk.)
For developers of external viewers for ADBV, the user manual presented in Appendix 3 contains a more complete description of all the data structures that may be used.
4.2.1 Naming conventions
Each package has one or more public classes that can be accessed from outside the package and a standard naming convention is followed throughout. All classes within a package that contain methods have their names prefixed with ADBV. Any classes that only store data, and as such, do not need any methods, do not have the ADBV prefix.
4.2.2 ADBVClient package
This package contains the classes needed for the Client program. The class ADBVClient can be executed to start the Client program. This package also contains the public interface ADBVViewerInterface, which must be implemented by all viewer applications.
ADBVClient 
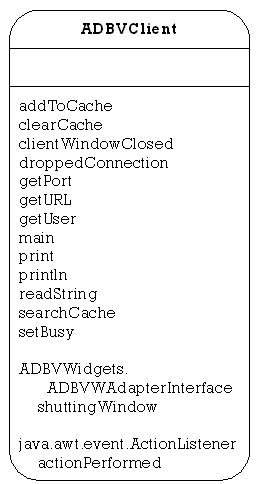 |
This is the main client class to be executed. It creates a user interface, with which the user can select the server with which to connect.
It contains functions to allow some of other client classes to access the cache and retrieve current information about server connection information.
|
ADBVClientCache
 |
This class contains all of the information about cached viewers. The details about each viewer are stored in instances of the CacheInfo class (see below).
|
ADBVClientClassLoader
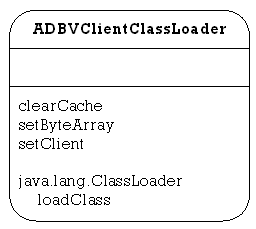 |
This class contains functions to allow creation of a specific Java class from an array of bytes.
|
ADBVClientClassThread
 |
This class contains three main functions that can be accessed by an external viewer. These form part of the ADBV API, which is explained in more detail in the User Documentation presented in Appendix 3.
One version of this class will be created for every viewer loaded, to act as an interface between the selection window (ADBVClientWindow) and the viewer itself.
ADBVclassClosing should be called by all viewers when they are closed by the user so that ADBV will not try and stop them itself.
ADBVgetConnection allows creation of a java.sql.Connection object to the database containing a specific table and using a specific user name and password if necessary.
ADBVgetTblName returns the table which was selected to start this viewer (e.g. this is useful if one viewer is used for more than one table, as the Default Viewer is).
println can be used by the viewer as well, to allow a message to be displayed in the main client window.
The other functions allow the calling ADBVClientWindow to communicate with each class thread, such as to stop it. Each thread is also given a unique identifier to allow it to be distinguished from other threads easily.
|
ADBVClientWindow
 |
This class creates the window that will be the focus of the user. It allows them to select a table for viewing and start up the related viewer. Many of these public functions are called from ADBVClientClassThreads. Some just pass on the call to the related ADBVClient to do the actual processing. Other functions allow the calling ADBVClient to communicate directly with this selection window.
|
ADBVDefaultViewer
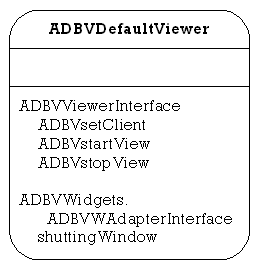 |
This class implements the ADBVViewerInterface defined below, and just displays whatever table is necessary using a standard list view type display. The file ADBV.gui is also required for this class to be used successfully.
|
ADBVViewerInterface 
 |
This interface must be implemented by all viewer applications. It forms the basis for the ADBV API, which is explained in more detail in the User Documentation of Appendix 3.
ADBVsetClient is called to allow the viewer to communicate directly with the client program.
ADBVstartView is called when the class has been loaded and created, and after ADBVsetClient has been called.
ADBVstopView is called by the client if the viewer has to be closed down automatically (e.g. if the user logs off from the server without closing down the viewer).
|
CacheInfo
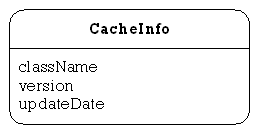 |
This class is used by the ADBVClientCache class above to store details about each viewer currently in the local cache.
|
ClassInfo
 |
This class is used by the ADBVClientWindow to store details about each of the currently executing viewers and the ADBVClientClassThread class associated with them.
|
TableStore
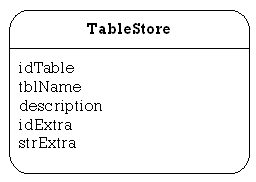 |
This class is used to store local information about each table that the client can view. Each table entry is then added into a Vector data structure.
|
4.2.3 ADBVServer package
This package contains the classes needed for the Server program. The class ADBVServer can be executed to start the Server program. Once the server has been started, it starts listening for clients using a single ADBVServerListener thread. For every client that then connects, a new ADBVServerThread structure is created with which the new client can communicate directly.
ADBVServer
 |
This is the main server class to be executed. It creates the user interface to allow connection to a template database, and starts a single ADBVServerListener thread to wait for clients wishing to connect.
|
ADBVServerListener
 |
This class runs as a separate thread, to listen for clients wanting to connect to this server. Once a client is accepted, a new ADBVServerThread process is created and the client is directed to talk to that process directly.
The clientsConnected function returns a boolean to say whether any clients are currently connected.
The stopThread function is called by an ADBVServerThread when it wishes to be stopped (i.e. when its associated client disconnects).
The stopListener function is called by the main ADBVServer class to stop this process from listening for any more clients.
|
ADBVServerThread
 |
For each connected client, there is one instance of this class. Communication between the client and server is done through this instance, and all commands are picked up by the run method within the thread, which then passes any command arguments on to a separate function to execute the command.
|
TableStore
|
This class is used to store local information about each table contained in the template database. As with ADBVClient.TableStore, each table entry is then added into a Vector data structure.
|
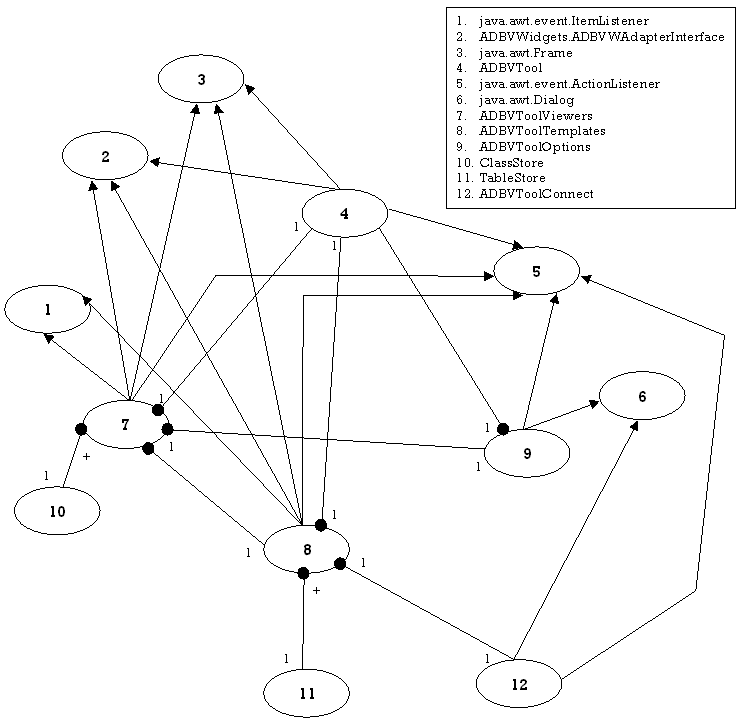
4.2.4 ADBVTool package
This package contains the classes needed for the Tool program. The class ADBVTool can be executed to start the Tool program. The tool allows templates to be set up for one or more data databases within any one template database.
ADBVTool
 |
This is the main Tool class to be executed. It creates the user interface to allow connection to any template database, or displaying of the editors necessary for editing templates and their associated viewers.
|
ADBVToolConnect
 |
This class creates a window to allow selection of the data database to create templates about at any one time.
|
ADBVToolOptions
 |
This class creates a window to allow updating of the options about the current template database.
|
ADBVToolTemplates
 |
This class creates a window to allow editing of the templates contained in the current template database. On entry to the screen, the user is presented with the ADBVToolConnect window to make the initial data database connection.
|
ADBVToolViewers
 |
This class creates a window to allow editing of the viewers to be used with the templates contained in the current template database.
|
ClassStore
 |
This class stores a copy of all of the information about the viewers loaded into the current template database. This allows the information to be displayed quickly and simply, without having to query the template database every time the details need to be viewed.
|
TableStore
 |
This class stores a copy of all of the information about the templates loaded into the current template database. This allows the information to be displayed quickly and simply, without having to query the template database every time the details need to be viewed.
|
4.2.5 ADBVWidgets
ADBVButton
 |
This class extends java.awt.Button to allow creation of buttons in a certain location on the screen and in a certain state with one single constructor call.
|
ADBVDDL
 |
This class extends java.awt.Choice to allow creation of drop down lists in certain locations on the screen and in a certain state with one single constructor call.
|
ADBVLabel
 |
This class extends java.awt.Label to allow creation of labels in certain locations on the screen and in a certain state with one single constructor call.
|
ADBVListBox
 |
This class extends java.awt.List to allow creation of list boxes in certain locations on the screen with one single constructor call.
|
ADBVMsgBox
 |
This class allows displaying of a message box with up to four lines of message and with three different button layouts - just an OK button; an OK and a Cancel button; a Yes and a No button.
In each case, the runMsg function returns a value to specify which button was pressed by the user.
This class is used throughout the three packages above to display error messages and questions to the user.
|
ADBVTextArea
 |
This class extends java.awt.TextArea to allow creation of text areas in certain locations on the screen and in a certain state with one single constructor call.
|
ADBVTextField
 |
This class extends java.awt.TextField to allow creation of text fields in certain locations on the screen and in a certain state with one single constructor call.
|
ADBVWAdapter
 |
This class is used by all windows throughout the ADBV package. It extends the standard Java AWT window event handler allowing windows to be closed and, if necessary, notified that they are being closed.
|
ADBVWAdapterInterface
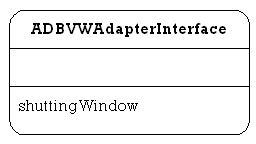 |
This interface is used by some of the windows in the ADBV package. The shuttingWindow function is called when the window is being closed, so that the related class can tidy up as necessary.
|
4.3.1 External files
There is one external file, relating to the Client program, which is needed to store details about viewers in the local cache. This cache will store each class’ name, version and update date. To simplify reading and writing of the cache details, this file is just a flat text file, with one cache entry per line, with each of the three fields (class name, version, update date) separated by character 0.
To signify the end of the cache entries, a single ‘.’ on its own at the beginning of a new line will be placed at the end of the file.
4.3.2 Database tables
To allow storing of template information, two database tables are needed. In addition, an extra table to store options is also needed.
T_CLASSES
Table T_CLASSES is used to store information and data about the external viewers.
It is currently created using the following SQL statement:
CREATE TABLE T_CLASSES (
IDCLASS INTEGER NOT NULL DEFAULT 0 PRIMARY KEY,
IDPARENTCLASS INTEGER NOT NULL DEFAULT 0,
CLASSNAME VARCHAR (255),
DESCRIPTION VARCHAR (255),
COPYRIGHT VARCHAR (255),
VERSION INTEGER NOT NULL DEFAULT 0,
UPDATEDATE DATE,
CLASSFILENAME VARCHAR (255),
CLASSLOADED SMALLINT NOT NULL DEFAULT 0,
CLASSDATA BLOB (65536)
)
IDCLASS stores a unique value for linking each table to a viewer.
IDPARENTCLASS stores a value to be used for linking classes together. This field is currently not used, but is included so that more than one class can be downloaded to create a viewer. The primary class will be the only one executed, and the others will be stored on the local file system so that they can be used by this primary class in the usual way.
CLASSNAME stores the name of the class to be loaded.
DESCRIPTION stores a description about this viewer.
COPYRIGHT stores copyright information about this viewer.
VERSION stores a version number for the viewer.
UPDATEDATE stores a date value signifying the last time that details about this viewer were changed.
CLASSFILENAME stores the location of where the viewer is stored on the local file system. This is currently not used, but is intended to allow databases that cannot store viewers within them to use local files instead.
CLASSLOADED contains a boolean value to signify whether or not a viewer is currently loaded into the CLASSDATA field.
CLASSDATA stores the actual Java application to be used as a viewer.
T_TABLE
Table T_TABLE is used to store the template information for each object.
It is currently created using the following SQL statement:
CREATE TABLE T_TABLE (
IDTABLE INTEGER NOT NULL DEFAULT 0 PRIMARY KEY,
IDCLASS INTEGER NOT NULL DEFAULT 0,
TABLENAME VARCHAR (255),
DESCRIPTION VARCHAR (255),
CON_CLASS VARCHAR (255),
CON_URL VARCHAR (255),
CON_USER VARCHAR (255),
CON_PASSWORD VARCHAR (255),
UPDATEDATE DATE
)
IDTABLE stores a unique value for each object for which a template is required.
IDCLASS contains a value for referring to the viewer to be used.
TABLENAME stores the name of the object this template to which is referring
DESCRIPTION stores a description about this object, which will be presented the client users.
CON_CLASS stores the class name of the driver to use for connecting to the data database containing this object.
CON_URL stores the URL of the database to use for connecting to the data database containing this object.
CON_USER stores the User Name for use when connecting to the data database containing this object.
CON_PASSWORD stores the Password for use when connecting to the data database containing this object.
UPDATEDATE stores a date value signifying the last time that details about this template were changed.
The two template tables (T_CLASSES and T_TABLES) are related by the IDCLASS field (Figure 4.3.1):
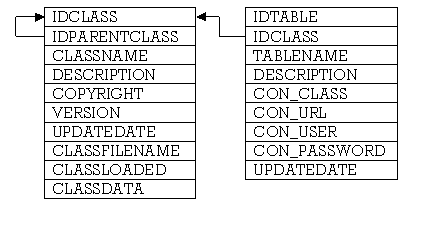
Figure 4.3.1
T_OPTIONS
Table T_OPTIONS is used to store details about options relating to the template database
It is currently created using the following SQL statement:
CREATE TABLE T_OPTIONS (
AUTO_STARTUP SMALLINT NOT NULL DEFAULT 0,
PORT_NUMBER INTEGER NOT NULL DEFAULT 8205,
HAS_TABLES SMALLINT NOT NULL DEFAULT 1
)
AUTO_STARTUP stores a boolean value to signify whether or not the client program will automatically show the first template specified using its viewer, or allow the user to choose which tables to view.
PORT_NUMBER stores the value of the port number that the server program should listen for clients on
HAS_TABLES stores a boolean value that is used to show that the three tables (T_TABLES, T_CLASSES, T_OPTIONS) have been created. This value is checked each time that either the tool or the server programs connect to the template database.
The following sub-sections present object diagrams for each of the Client, Server and Tool programs using the data structures defined above, linked together using the following interconnects:
4.4.1 Client
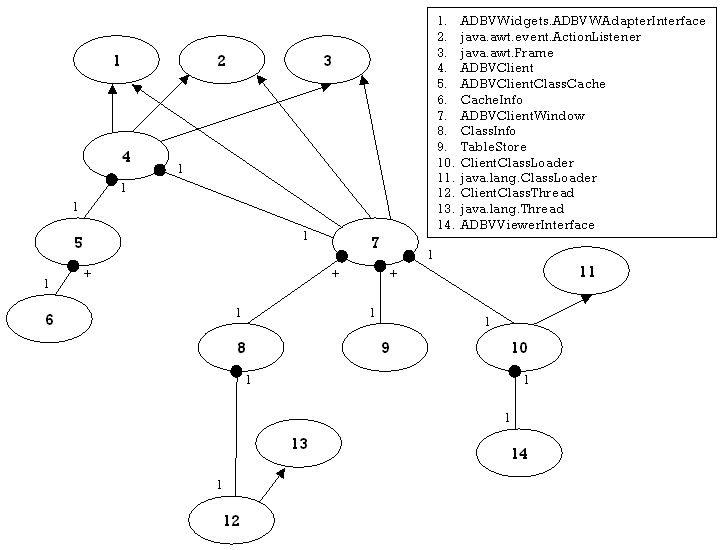
4.4.2 Server
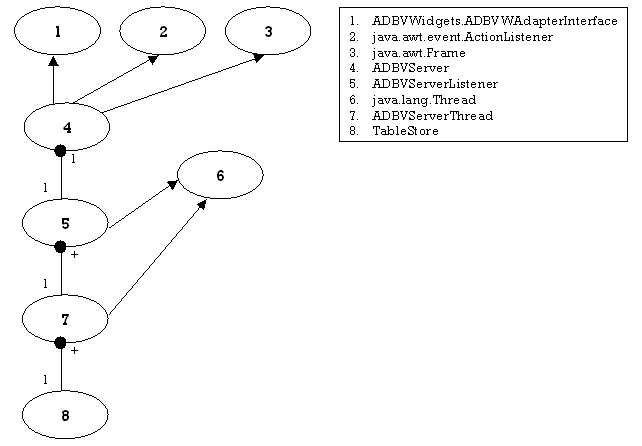
4.4.3 Tool
Each of the programs is to be continuously tested during development, followed by a test of the complete system when finished. Any bugs will be fixed if possible and the programs and system tested again.
The development of ADBV has involved high learning curves at times. This all began with learning how to program in Java, and in particular, how to use IBM Visual Age for Java (VAJ), and create and access databases using IBM DB2 along with JDBC [12]. This knowledge was developed from previous experience in C++ and the Microsoft Access database. The transition from C++ to Java was not too great, but the specifics of calls to JDBC, especially alongside DB2, were more difficult to learn at times.
Apart from this, most of the Java code was not too difficult to write or find out about how to write, and so the development has been quite smooth throughout the project. However, during this development two major problems have arisen which did slow the progress of the project.
The first was the problem of loading a Java application into memory and executing it. This needed to be done, so that the viewers for each template could be loaded and executed. The problem was solved by extending the java.lang.Classloader class (ADBVClient.ADBVClientClassLoader) to load the viewer application into memory and then create a new instance of it.
The second problem was how to save and retrieve the Java application to and from the BLOB field within the T_CLASSES table. This problem took a lot longer to solve and stopped development for a few weeks whilst pleas for help and ideas were sent out to many different people. This problem was finally resolved though, using java.io.BinaryStreams and java.sql.PreparedStatements, which allowed for the transfer of large amounts of binary data to and from the database.
The accompanying disk contains all source code listings for the Abstract Database Viewer. (See Appendix 2 for information about the accompanying disk.)
The User Documentation is presented in Appendix 3
The source code is well documented, and JavaDoc has been supplied and created. With reference to this and the data flow diagrams and data dictionary presented in Appendix 1, along with the data structures and object diagrams presented in Section 4 above, it should be possible to maintain the packages as they stand.
Currently, the system will only allow the use of template databases running on IBM’s DB2 database. When the template tables are created in the function checkTablesExist in class ADBVTool.ADBVTool, the data type BLOB is used to create one of the fields in table T_CLASSES. This will need to be changed for any database that does not understand the BLOB data type. In addition, when this field is created, it has a maximum size limit of 64Kb. To update this value, change the creation statement in checkTablesExist and update the maxBLOBsize constant defined in class ADBVTool.ADBVToolViewers to the same value.
A similar problem with accessing databases is that of doing so by the client user program, as the system is only distributed with the JDBC drivers necessary for accessing DB2 databases. It has been left to the viewer application developer as to how to provide the necessary drivers for accessing the data databases.
The complete package has been designed using JDK v.1.1. It is believed that the package will not work under v.1.0 or v.1.2, as certain event models are different in each case, and errors will occur throughout if the programs are not executed under v.1.1.
6.1.1 Introduction
This section presents a plan for the testing of the Abstract Database Viewer. In using this plan, any inadequacies in the package will be found and reported on in the Test Report presented in section 6.2.
6.1.2 Test Coverage
The general areas that need to be covered in the test plan are as follows:
-
Program execution
Check that the program executes successfully
-
Tool
Check that the tool allows template databases to be created and manipulated successfully
-
Server
Check that the server program works successfully
-
Client
Check that the client program works successfully
-
Client / Server
Check that the client / server interaction works correctly and successfully
-
System
Check that the whole system has a common look and feel and that all errors are contained within the programs
6.1.3 Format of Test Plan
The two example tables below show the general layout of the tables used in the test plan.
The first shows all the tests to be carried out, ordered by test number and showing the corresponding test script numbers and the function that is being examined in each case.
| No. |
Script No. |
Function |
What it is testing for |
| EG1 |
1 |
Function of test |
Purpose of test |
The second table shows actual test scripts to be carried out, ordered by test script number. A description is given of how the test should be performed, followed by the criteria to be met in order for the test to pass.
| No. |
What to do
Pass Criteria
|
| 1 |
How to perform the test
Requirements for the test to pass
|
6.1.4 Program Execution
| No. |
Script No. |
Function |
What it is testing for |
| PE1 |
1, 2 |
Start up |
Tests that all programs start up successfully |
| PE2 |
3 |
Exit |
Tests that all programs exit successfully |
6.1.5 Tool
These tests assume that the tool program has been started
| No. |
Script No. |
Function |
What it is testing for |
| T1 |
4 ® 7 |
Connect |
Connecting to a template database successfully, ignoring bad parameters |
| T2 |
8, 36, 37 |
Disconnect |
Closing connection to a template database successfully |
| T3 |
9 ® 11, 55 |
Viewers |
Opening of Viewer Editor window in a default state |
| T7 |
12 ® 14 |
|
Updating viewer information |
| T5 |
15 ® 21 |
|
Adding a viewer |
| T6 |
22, 23 |
|
Deleting a viewer |
| T7 |
24, 55 |
|
Updating a viewer application |
| T8 |
25 |
|
Checking viewer has been saved successfully |
| T9 |
32, 33 |
|
Removing a viewer application |
| T10 |
26 |
Templates |
Opening of Template Editor window in a default state |
| T11 |
4 ® 6, 27 |
|
Connecting to a data database successfully, ignoring bad parameters |
| T12 |
28 |
|
Adding a template |
| T13 |
29 |
|
Deleting a template |
| T14 |
30 |
|
Connecting to a new data database |
| T15 |
31 |
|
Updating template information |
| T16 |
33 |
|
Updating of viewer application list successfully |
| T17 |
34, 58 |
Options |
Opening of options window in a default state |
| T18 |
35, 58 |
|
Editing of information |
6.1.6 Server
These tests assume that the server program has been started
| No. |
Script No. |
Function |
What it is testing for |
| S1 |
4 ® 6, 38 |
Connecting |
Connecting to a template database successfully, ignoring bad parameters |
| S2 |
39, 56, 57 |
Disconnect |
Closing connection to a template database successfully |
| S3 |
40, 43 |
Starting |
Starting a process to listen for, and connect clients |
| S4 |
41, 57 |
Stopping |
Stopping the listener process, making sure that there are no open connections |
6.1.7 Client
These tests assume that all programs have been started
| No. |
Script No. |
Function |
What it is testing for |
| C1 |
42 ® 45 |
Logon |
Logging on to a server successfully, ignoring bad parameters |
| C2 |
57 |
Logoff |
Logging off from a server successfully |
| C3 |
46, 50, 52, 55, 58 |
Viewing data |
Viewing data through loaded viewers |
| C4 |
47 |
|
Viewing data through default viewer |
| C5 |
48 ® 52 |
|
Windows are tidied up automatically |
| C6 |
50, 53 ® 55, 58 |
|
Cache is functioning correctly |
| C7 |
53 |
|
Clearing the cache |
| C8 |
58 |
Auto Startup |
Auto startup functionality works successfully |
6.1.8 System
| No. |
Script No. |
Function |
What it is testing for |
| SYS1 |
60 |
Execution |
Common look and feel |
| SYS2 |
61 |
Errors |
Are all errors handled by the program |
6.1.9 Test Scripts
| No. |
What to do Pass Criteria |
| 1 |
Execute each program in turn with no parameters Should start up without error |
| 2 |
Execute each program in turn with some parameters Should start up without error, ignoring the parameters |
| 3 |
Select the ‘Exit’ button in each program once they are running Should exit without error |
| 4 |
Enter invalid URL. Select ‘Connect’ button Should inform the user that the URL was invalid |
| 5 |
Enter invalid Driver. Select ‘Connect’ button Should inform the user that the Driver was invalid |
| 6 |
Enter valid URL and Driver with invalid User and Password. Select ‘Connect’ button Should inform the user that the user name was invalid |
| 7 |
Clear User and Password. Set URL and Driver to the test template database. Select ‘Connect’ button Should connect to database and enable ‘Viewers’, ‘Templates’ and ‘Options’ buttons |
| 8 |
Select ‘Close’ button Should disconnect from database and disable ‘Viewers’, ‘Templates’ and ‘Options’ buttons |
| 9 |
Select ‘Connect’ button. Select ‘Viewers’ button. Should open Viewer Editor window and disable ‘Viewers’ button |
| 10 |
Try to edit fields They should not be editable |
| 11 |
Select ‘Update’ button Nothing should happen |
| 12 |
Select ‘ConsTK’ viewer from ‘Current Viewers’ list Details should update to reflect this selection |
| 13 |
Set version number to ‘2’. Select ‘Update’ button Details should be updated successfully |
| 14 |
Set version number to ‘blah’. Select ‘Update’ button Should be informed of invalid version number, and version number should be set back to 2 |
| 15 |
Select ‘Add’ button Should be presented with file dialog box |
| 16 |
Enter invalid filename. Select ‘OK’ button Should be told that this file name is not valid |
| 17 |
Select ‘Add’ button. Select ‘Cancel’ button Should return to original state |
| 18 |
Select ‘Add’ button. Select file without ‘.class’ extension Should ask to make sure that this file is to be imported. |
| 19 |
Select ‘No’ button. File should not be imported |
| 20 |
Select ‘Add’ button. Select file without ‘.class’ extension. Select ‘Yes’ button File should be imported, and details be updated to reflect new file |
| 21 |
Select ‘Add’ button. Select file with ‘.class’ extension File should be imported, and details be updated to reflect new class |
| 22 |
Select second viewer in list. Select ‘Delete’ button List should be updated to reflect deletion |
| 23 |
Select last viewer in list. Select ‘Delete’ button List should be updated to reflect deletion |
| 24 |
Select ‘Add’ button. Select file with ‘.class’ extension. Select ‘OK’ button. Select ‘Update Class’ button. Select new file with ‘.class’ extension. Select ‘OK’ button Should update viewer information accordingly |
| 25 |
Close Viewer Editor window. Select ‘Viewers’ button. Select each viewer in turn Window should close successfully, and then on reopening, the new details should be set up as they were before the window was closed. |
| 26 |
Select ‘Templates’ button on main window Template Editor window should open successfully, with New Connection window on top. |
| 27 |
Clear User and Password. Enter correct Driver and URL for test database. Select ‘Connect’ button Should connect successfully and show objects in ‘Selectable Objects’ list which are not already in ‘Current Templates’ list. ‘Add’ and ‘Delete’ buttons should be disabled |
| 28 |
Select an object from the ‘Selectable Objects’ list. Select ‘Add’ button Should remove object name from lower panel and add to ‘Current Templates’ list, setting up details and displaying them |
| 29 |
Select ‘Delete’ button Template should be removed from ‘Current Templates’ list and added to ‘Selectable Objects’ list, refreshing screen as necessary |
| 30 |
Select ‘Connect’ button. Connect to test template database Should clear ‘Selectable Objects’ list, as there are no usable object in the template database |
| 31 |
Select ‘Q_PROJECTS’ object from ‘Current Templates’ list. Change Description to ‘Projects’. Select ‘Update’ button Details should be saved successfully |
| 32 |
On Viewer Editor window, select second viewer in list. Select ‘Clear’ button. Select ‘No’ Class should not be cleared |
| 33 |
Select ‘Clear’ button. Select ‘Yes’ Class should be cleared, and viewer list on Templates Editor window should be updated to reflect the fact that no class is loaded into this viewer. |
| 34 |
On main window, select ‘Options’ button Options window should open with default view |
| 35 |
Change Port number to 8305. Select ‘OK’ button. Select ‘Options’ button on main window. Select ‘Cancel’ button Port number should have been updated to 8305 |
| 36 |
Select ‘Close’ button on main window Template Editor and Viewer Editor windows should close, and connections to databases be closed as well |
| 37 |
Select ‘OK’ on New Connection window. Select ‘Viewers’ button on main window. Select ‘Exit’ button on main window. Template Editor and Viewer Editor windows should close, and connections to databases be closed as well. Tool should exit without error. |
| 38 |
Clear User and Password. Set URL and Driver to the test template database. Select ‘Connect’ button Should connect to database, enable ‘Start’ button and set caption on ‘Connect’ button to ‘Close’ |
| 39 |
Select ‘Close’ button Should disconnect from database, disable ‘Start’ button and set caption on ‘Close’ button to ‘Connect’ |
| 40 |
Select ‘Connect’ button. Select ‘Start’ button when enabled Should start up a listener process and show that the process was started successfully and that clients can now connect, along with setting the caption on the ‘Start’ button to ‘Stop’, and disabling the ‘Close’ button |
| 41 |
Select ‘Stop’ button Should stop listener process and show that the process has been stopped, and that no more clients can connect, along with setting the caption on the ‘Stop’ button to ‘Start’ and enabling the ‘Close’ button |
| 42 |
Select ‘Logon’ button on Client. Logon should fail and the user should be told |
| 43 |
Select ‘Start’ button on Server. Select ‘Logon’ button on Client Logon should fail (as the port number is invalid) and the user should be told |
| 44 |
Enter invalid Host name. Select ‘Logon’ button on Client Logon should fail and the user should be told |
| 45 |
Enter valid Host name. Set Port to 8305. Select ‘Logon button Logon should succeed. Tables window should appear with a list of all the tables referenced in the template database. |
| 46 |
Select ‘Projects’ table from list. Select ‘Show’ button Construction Toolkit program should be loaded successfully and shown to the user |
| 47 |
Select ‘Organisations’ table from list. Select ‘Show’ button Organisations table should be loaded into default viewer and shown to the user |
| 48 |
Close "ORGS - Default Viewer" window. Close "Construction Toolkit" window. Close "ADBV Client: Tenplates" window ‘Templates’ and ‘Clear Cache’ buttons should be enabled |
| 49 |
Select ‘Templates’ button. "ADBV Client: Templates" window should reopen and ‘Templates’ and ‘Clear Cache’ buttons should be disabled |
| 50 |
Select ‘Projects’ table from list. Select ‘Show’ button Construction Toolkit should be reloaded, but this time, from disk instead of being downloaded from the server |
| 51 |
Close "ADBV Client: Templates" window Construction Toolkit windows should be closed |
| 52 |
Select ‘Templates’ button. Select ‘Projects’ table from list. Select ‘Show’ button twice. Select ‘Organisations’ table from list. Select ‘Show’ button. Close "ADBV Client: Templates" window Two copies of Construction Toolkit should be loaded, along with one Default Viewer showing the ORGS table. On close of "ADBV Client: Templates" window, all loaded viewers should also be closed. |
| 53 |
Select ‘Clear Cache’ button Cache should be cleared, and ‘Clear Cache’ button should be disabled |
| 54 |
Select ‘Templates’ button. Select ‘Projects’ table from list. Select ‘Show’ Viewer should be downloaded from server again, rather than loaded from local disk |
| 55 |
Select ‘Connect’ on Tool. Select ‘Viewers’ on Tool. Select ‘ConsTK’ class from list. Update version number to one that is higher than the currently one. Select ‘Close’ on main Tool window. Select ‘Show’ button on Client "ADBV Client: Templates" window. Viewer should be downloaded from server again, as the version number has been updated |
| 56 |
Select ‘Stop’ on Server. Server should not be able to stop, as there is still a client connected |
| 57 |
Select ‘Logoff’ on Client. Select ‘Stop’ on Server. Select ‘Close’ on Server. Listener process should stop successfully and connection to database should be closed successfully. All Client windows should be closed |
| 58 |
Select ‘Connect’ on Tool. Select ‘Options’ on Tool. Set Auto Startup option to on. Select ‘OK’ button on "Options" window. Select ‘Close’ on Tool. Select ‘Connect’ on Server. Select ‘Start’ on Server. Select ‘Logon’ on Client On logon by Client, ‘Templates’ button should not be shown on main window this time, and the "ADBV Client: Templates" window should not automatically load, but instead, just the Construction Toolkit window should be loaded from disk immediately. |
| 59 |
Select ‘Exit’ on Server. Server should not be able to stop immediately, as there is still a client connected, but it should be possible to exit if necessary. |
| 60 |
Run all executable programs and examine their appearance and the way they interact with the user. There should be a common look and feel throughout |
| 61 |
Put in junk data and long text strings (longer that 255 characters), along with pressing any buttons possible, and generally trying to make the program error All errors should be trapped and, if necessary, the user should be notified through the program. All messages should appear within the environment of each program, and not on the command line |
6.2.1 Introduction
This section presents a report of the testing of the Abstract Database Viewer as described in the plan of section 6.1.
6.2.2 Format of Test Report
The two example tables below show the general layout of the tables used in the test report.
The first table references the tests (as described above) by test number and script number and indicates whether this test passed or failed. If the test failed, then a report number is given, which links this table to the second table.
| Test No. |
Script No. |
Pass / Fail |
Report No. |
| EG1 |
1 |
Pass |
|
| EG2 |
2 |
Fail |
1 |
The second table shows what went wrong and gives an indication as to the importance of fixing the problem. The ‘Report No.’ column links back to the ‘Report No.’ column in the first table.
| Report No. |
Report Description |
Fix Priority |
| 1 |
Why the test failed |
1 |
The fix priority values can be 0, 1, 2 or 3, where each priority has the following meaning:
- A fault which has been fixed (original priority given in brackets)
- A major fault that needs to be fixed
- A less major fault, but still a problem which needs to be fixed
- A minor annoyance, which it would be nice to fix.
6.2.3 Test Report
| Test No. |
Script No. |
Pass / Fail |
Report No. |
| PE1 |
1 |
Pass |
|
|
2 |
Pass |
|
| PE2 |
3 |
Pass |
|
| T1 |
4 |
Pass |
|
|
5 |
Pass |
|
|
6 |
Pass |
|
|
7 |
Pass |
|
| T2 |
8 |
Pass |
|
|
36 |
Pass |
|
|
37 |
Pass |
|
| T3 |
9 |
Pass |
|
|
10 |
Fail |
1 |
|
11 |
Pass |
|
|
55 |
Pass |
|
| T4 |
12 |
Pass |
|
|
13 |
Pass |
|
|
14 |
Fail |
2 |
| T5 |
15 |
Pass |
|
|
16 |
Fail |
3 |
|
17 |
Pass |
|
|
18 |
Pass |
|
|
19 |
Pass |
|
|
20 |
Pass |
|
|
21 |
Pass |
|
| T6 |
22 |
Pass |
|
|
23 |
Pass |
|
| T7 |
24 |
Fail |
4 |
|
55 |
Pass |
|
| T8 |
25 |
Pass |
|
| T9 |
32 |
Pass |
|
|
33 |
Pass |
|
| T10 |
26 |
Pass |
|
| T11 |
4 |
Pass |
|
|
5 |
Pass |
|
|
6 |
Pass |
|
|
27 |
Pass |
|
| T12 |
28 |
Pass |
|
| T13 |
29 |
Pass |
|
| T14 |
30 |
Pass |
|
| T15 |
31 |
Pass |
|
| T16 |
33 |
Pass |
|
| T17 |
34 |
Pass |
|
|
58 |
Pass |
|
| T18 |
35 |
Pass |
|
|
58 |
Pass |
|
| S2 |
4 |
Pass |
|
|
5 |
Pass |
|
|
6 |
Pass |
|
|
38 |
Pass |
|
| S2 |
39 |
Pass |
|
|
56 |
Pass |
|
|
57 |
Pass |
|
| S3 |
40 |
Pass |
|
|
43 |
Pass |
|
| S4 |
41 |
Pass |
|
|
57 |
Pass |
|
| C1 |
42 |
Pass |
|
|
43 |
Pass |
|
|
44 |
Pass |
|
|
45 |
Pass |
|
| C2 |
57 |
Pass |
|
| C3 |
46 |
Pass / Fail |
5 |
|
50 |
Pass / Fail |
5 |
|
52 |
Pass / Fail |
5 |
|
55 |
Pass / Fail |
5 |
|
58 |
Pass / Fail |
5 |
| C4 |
47 |
Pass |
|
| C5 |
48 |
Pass |
|
|
49 |
Pass |
|
|
50 |
Pass |
|
|
51 |
Pass |
|
|
52 |
Fail |
6 |
| C6 |
50 |
Pass |
|
|
53 |
Pass |
|
|
54 |
Pass |
|
|
55 |
Pass |
|
|
58 |
Pass |
|
| C7 |
53 |
Pass |
|
| C8 |
58 |
Pass |
|
| SYS1 |
60 |
Pass |
|
| SYS2 |
61 |
Pass |
|
| Report No. |
Report Description |
Fix Priority |
| 1 |
Fields were editable, even though no viewer was selected |
0 (2) |
| 2 |
The viewer information was not saved, but no message was given as to why, and ‘blah’ was left as the version number |
0 (2) |
| 3 |
The filename was not reported as being invalid until after the program had tried to load the file |
0 (2) |
| 4 |
Viewer details not updated |
0 (1) |
| 5 |
Under IBM Visual Age for Java, which uses a version of JDK 1.1.2, the test passed without error. Under JDK 1.1.5, the Java application would not load properly, due to an Illegal Access Exception when the program tried to create a new instance of it. |
0 (1) |
| 6 |
All windows, except Default Viewer ones are closed. |
0 (1) |
Written in Java, to be platform independent, the Abstract Database Viewer (ADBV) has been developed as a solution to certain problems of accessing information contained in databases through the Internet. Currently there are standard mechanisms for gaining access to this information, but no methods in place for actually viewing the information, unless it is in a standard textual, numerical, or graphical format.
The development of the ADBV system has proved that the use of a template mechanism and an API can allow information of any format to be viewed across the Internet by client users through a standard interface. The templates consist of the data to be accessed, along with a viewer application that understands the format of this data. The API then allows the viewer applications to interact with the ADBV system.
The development has also sought to provide the database administrator with a means to set up the templates as quickly and as easily as possible. This is achieved through a management tool that allows the administrator to view a list of the objects contained within a database. Objects can be selected from this list and templates created about them. The viewer application for each template can then be chosen from a simple choice list of those that are currently available on the system.
Through the creation of ADBV, the developer has acquired new skills. These skills include programming Java, both in the learning of the language and in learning the specifics of using network sockets, accessing databases, and loading Java modules dynamically. Experience of IBM DB2 has also been useful, due to its wide use throughout the world of business and across machine architectures. Additionally, the development environments have been relatively easy to use and, both IBM Visual Age for Java and IBM DB2 have provided a stable working environment most of the time. However, both packages were quite memory intensive and the documentation was not as accessible as standard MS-Windows Help.
For enhancement of the ADBV solution, further research must be undertaken. The design of the current system involved some extensions, but the time constraint did not allow these to be implemented. Other ideas for research areas have yet to reach the design stage.
Extensions
Security Mechanism
Some development of a security mechanism is needed. This should be through client users sending a user name and password combination to the server for verification before they can gain access to the data.
Multiple modules per viewer
Some development of a mechanism by which multiple Java classes can be stored for use by a single viewer is also needed. This could be done in one of two ways
-
Using separate records in the template database
Each separate module could be stored in a separate record in the template database. These could be linked to a primary module that would interact with ADBV. The current T_CLASSES table contains this link, and comments in the code show where changes are necessary for this to be implemented.
-
Using the Java Archive (JAR) file structure
This structure allows multiple modules to be stored in one flat file. This file could then be loaded into the template database and accessed using a similar mechanism to that currently implemented.
Research Areas
Client / Server interaction through CORBA
Communication between client and server systems in ADBV currently uses network sockets. Alternatively, the Common Object Request Broker Architecture (CORBA) [4, 11] could be used, allowing the viewer applications to be programming language independent. In addition, the client user would not need to enter the physical location of the server program, as the ORB provides the necessary mechanisms for location transparency [4].
Enhancement of template structure and management tool
Currently, the structure of the templates is a very simple link between object and viewer, which has to be created by the database administrator. This is done using the management tool, which displays the available objects, by reading a subset of the meta-data [2] contained within the database. The primary-key and foreign-key meta-data about each table could also be used to display the actual relationships between different tables, leading to a more meaningful representation of the data being created.
- Gary Cornell and Cay S. Horstmann, Core Java, Second Edition, Prentice Hall, 1997
- Prashant Sridharan, Advanced Java Networking, Prentice Hall, 1997
- S. Ceri and G. Pelgatti, Distributed Databases: Principles and Systems, McGraw-Hill, New York, 1984
- Andreas Vogel and Keith Duddy, Java Programming with CORBA, Wiley Computer Publishing, 1997
- Steve O’Connell, CM323 Advanced Databases Course Notes, Department of Electronics and Computer Science, Southampton University, 1998
- Roger S. Pressman, Software Engineering, A Practitioner’s Approach, McGraw Hill International (UK) Ltd., 1994
- Mark Papiani, Alistair N. Dunlop and Anthony J. G. Hey, Automatically Generating World-Wide Web Interfaces to Relational Databases, University of Southampton, 29th November, 1996
- Bernard Van Haecke, JDBC Java Database Explorer, 1996
- Flavio A. Bergamaschi, Mark Papiani,Koh Sin Huat, and Ed Zaluska, BenchView: Java Tool for Navigation, Retrieval and Visualisation of Databases of Parallel Benchmark Results, University of Southampton
- Alistair Dunlop, Mark Papiani and Tony Hey, Providing Access to a Multimedia Archive using the World-Wide Web and an Object-Relational Database Management System, University Of Southampton, 12th July, 1996
- Ron I. Resnick, Bringing Distributed Objects to the World Wide Web, 1996
- JDBC™ Guide: Getting Started, Sun Microsystems Inc, 1997
- Marimba, http://www.marimba.com
- IBM, http://www.ibm.com, http://www.ibm.com/java
- Sun Microsystems Inc.
, http://www.sun.com, http://java.sun.com
- Microsoft
, http://www.microsoft.com
- Symantec
, http://www.symantec.com
- Java Developer Connection, http://java.sun.com/jdc
- Developer.com, http://www.developer.com
- Gamelan, http://www.gamelan.com
The following pages present the data flow diagrams created during the design stage for the Abstract Database Viewer. These are followed by the Data Dictionary.
Accompanying this report, is a disk that contains a standard MS-Windows ZIP file (ADBV.ZIP) with an image of the following directories contained within it.
- bin
The complete Administrative version of ADBV with JDBC drivers for accessing DB2 databases. This can be used as explained in the User Documentation presented in Appendix 3.
- Client
The client version of ADBV for distribution.
- JavaDoc
Automatically generated HTML files about each package and its public data structures.
- Source
Java source code for the three ADBV programs.
- Tutorial
A set of files which allow the user to follow a tutorial through to create the example databases and use them with ADBV. The User Documentation presented in Appendix 3 explains how to access this tutorial.
The following pages present the User Documentation for the Abstract Database Viewer.
Theo Gray: [email protected]
http://www.madtech.force9.co.uk